
티스토리 뷰
> Deep Learning은 ML과 메커니즘과 Code Flow가 다름 (pytorch)
> Pytorch 하려면 Class 알아야 함


> Class는 객체를 만들기 위한 설계도 혹은 틀 (붕어빵 틀), 연관되어 있는 변수와 메서드(객체 안의 함수)의 집합
> 객체(Object)는 실제로 만드는 붕어빵. 객체의 모든 인스턴스를 대표하는 포괄적인 의미.
> 객체는 Instance라고 생각하면 된다.
> 예) 철수는 인스턴스 철수의 클래스는 사람
> 예) 소나타는 클래스 차의 종류, 인스턴스는 각각의 소나타의 차

#Class
class Country01:
name = '국가명'
capital = '수도'
population = 100
def introduce(self):
sentence = '국가 소개'
return sentence
exp = Country01()
print(exp.name,'\n')
print(exp.capital, '\n')
print(exp.introduce(), '\n')

> Class 명의 첫 글자는 대문자
> ex1 = Coutry01()의 ex1은 instance다, 설계도가 Country01
> ~. 의 의미는 Class 안에 변수나 메서드를 사용
>.()은 클래스,. 은 변수

class C2:
def __init__(self, name, capital, population):
self.name = name
self.capital = capital
self.population = population
def introduce(self):
sentence = '국 소'
return sentence
c2 = C2(name = 'JY', capital ='Seoul', population = 300)
print(c2.name)
print(c2.population)
print(c2.introduce())
> 변수를 사용자가 정하도록 튜닝하는 방법은 init 활용
> init 초기화이며 self를 넣어줘야 함 instance가 자기 자신이란 의미

class C1:
name = '국가명'
capital = '수도'
population = 100
def introduce(self):
sentence = '국가 소개'
return sentence
class C3(C1):
def __init__(self, name):
self.name = name
def explanation(self):
sentence = f'국가 이름은 {self.name}'
return sentence
ex3 = C3(name='한국')
print(ex3.name)
print(ex3.capital)
print(ex3.explanation())
print(ex3.introduce())
> 상속은 부모(Super) 클래스의 변수와 메서드를 자식(Sub) 클래스가 물려받는다.
> 클래스 수정하면 인스턴스 ex3를 다시 선언해줘야 한다.

> Sub 클래스에서 부몬의 메서드를 덮어 씌운다,

class C1:
name = '국가명'
capital = '수도'
population = 100
def introduce(self):
sentence = '국가 소개'
return sentence
class C4(C1):
def __init__(self, name):
self.name = name
def introduce(self):
res1 = super().introduce()
res2 = '한국'
return res1, res2
c4 = C4(name = '한국국')
c4.introduce()

a1_torch = torch.FloatTensor(range(1,10))
print(a1_torch)
print(a1_torch.dim()) #차원
print(a1_torch.size())
print(a1_torch[0])
print(a1_torch[2:5])
a2 = np.arange(0,12).reshape(4,-1)
a2_torch = torch.FloatTensor(a2)
print(a2_torch)
print(a2_torch.dim())
print(a2_torch.size())
print(a2_torch[:,1])
print(a2_torch[:,:-1].size())
> Deep Learning에서 pytorch만 쓰고 numpy 안 씀, pytorch 자료형이 더 빠르기 때문
> list 계산보다 numpy array 구조의 계산이 더 빠르기 때문에 numpy 사용
a3 = torch.FloatTensor([1,2])
print(a3.dim())
print(a3.size())
a4 = torch.FloatTensor([[1,2]])
print(a4.dim())
print(a4.size())
> 대괄호 []는 1차원, size 2, [[]] 2차원, 완전히 다르게 인식하기 때문에 주의해야 한다.

> Pytorch에서 괄호 차이가 나도 괄호 많은 기준으로 연산을 해준다.

> 행 벡터와 열 벡터를 더하면 행렬로 연산 처리되어 나옴
v1 = torch.FloatTensor([[3,3]])
v2 = torch.FloatTensor([5,5])
print(v1+v2)
v3 = torch.FloatTensor([[1,2]])
v4 = torch.FloatTensor([3])
print(v3 + v4)
v5 = torch.FloatTensor([[1,2]])
v6 = torch.FloatTensor([[3], [4]])
print(v5 + v6)
#행렬 곱 / 원소 곱
m1 = torch.FloatTensor([[1,2],
[3,4]])
m2 = torch.FloatTensor([[5],
[6]])
print(m1.matmul(m2))
print(m1*m2)
print(m1.mul(m2))
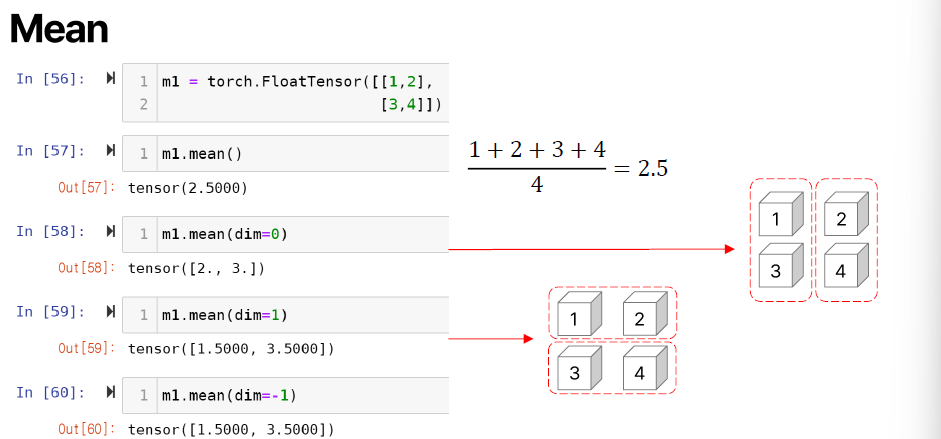
> dim = -1 은 0, 1 중 큰 값으로 반환

> indcies은 index이고 argmax/argmin 값이고 [0]은 value, [1]은 index이다.
print(m1.mean())
print(m1.mean(dim=0))
print(m1.mean(dim=1))
print(m1.mean(dim=-1),'\n')
print(m1.sum())
print(m1.sum(dim=0))
print(m1.sum(dim=1))
print(m1.sum(dim=-1),'\n')
print(m1.max())
print(m1.max(dim=1))
print(m1.max(dim=0)[0])
print(m1.max(dim=0)[1])


> 대괄호가 [[[ ]]] 이면 tensor이다
> Tensor에서 행렬의 개수를 채널(Channel)이라고 표현한다. 2개면 채널이 2다.
> (채널, 행, 열)
> View 함수로 tensor로 행렬로 바꿀 수 있다.
> view에서 -1은 알아서 나눈다.
a = np.arange(1,13).reshape(-1,4)
b = np.arange(13,25).reshape(-1,4)
t = torch.FloatTensor([a,b])
print(t.shape)
print(t.size())
print(t.view([-1,3]))
print(t.view([-1,1,3]))



> ones, zeros는 append 방식 말고 지정해서 데이터를 넣어줄 때 많이 활용됨
> append 방식보다 장점은 output의 크기가 정해져서 크기가 다를 오류를 줄일 수 있다.
x = torch.FloatTensor([1,4])
y = torch.FloatTensor([2,5])
z = torch.FloatTensor([3,6])
print(torch.stack([x,y,z]))
print(torch.stack([x,y,z], dim =1))
print(torch.cat([x.unsqueeze(0),y.unsqueeze(0),z.unsqueeze(0)])) #이렇게도 할 수 있는데 stacking이 더 편함
#one, zeros
print(torch.ones_like(x))
print(torch.zeros_like(x))
#In place Operation
x.mul(2)
print(x)
x.mul_(2)
print(x)




> OR, AND 연산은 직선 하나로 구분이 가능하지만, XOR는 구분할 수 없음


> 비선형 방식으로 해결하려고 함
> 이 방식이 Deep Learning(신경망)이다.
> 원 하나당 Node라고 한다.

> max 값 0.9, argmax 값 레몬

> 입력값은 피쳐들이고 w만큼 가중된다.
> 가중합은 내적 값이 되고 딥러닝에서 가중합이라고 표현한다.
> 활성화 함수는 다른 퍼셉트론(뉴런 신경)에 전달할지 말지 정한다.
> 가중합이 t 보다 크면 1로 출력, 작으면 0으로 출력하며 이 함수를 activation function이라고 한다.

> 합쳐서 표현 많이 함

> t를 0으로 만들고 상수항(bias) b를 넣을 수 있다.
> 위의 식은 지시 함수로 표현.


> 딥러닝에서 함수를 f 대신 파이로 많이 쓴다.
> Sigmoid 함수 (Logistic Regression에서 나옴)의 장점은 미분 가능하고 0과 1 사이 실수가 존재한다. (다양한 값 존재)
> 활성화 함수는 Hyper Parameter

> 포도 이미지의 데이터가 있다고 하면 신경망 태우면 가중합을 하게 된다.
> 가중합은 최종적으로 구하는 값
> 가중합이 -2가 나왔다면 시그모이드 함수를 거쳐서 0.119가 나온다.
> 0.119는 레몬일 확률이다.
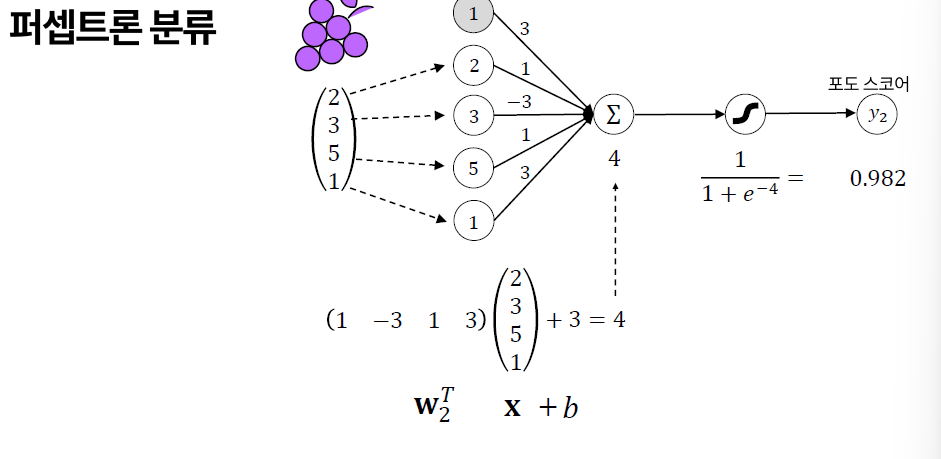
> 0.982는 포도일 확률

> 레몬, 포도 Score 합쳐서 포도로 선택
> W는 가중치 행렬, x는 피처, b는 바이어스.
> 가중치 행렬의 원소 개수는 8개이고 화살의 개수이다.
> ML에선 구해야 되는 값은 보통 피처 x의 개수이다 하지만 딥러닝은 x의 2배이다.
> 더 복잡한 신경망에서 구해야 되는 parameter 수는 매우 많다.
> 연산이 많아서 결과는 알 수 있으나 그 과정이랑 왜 그런 결과가 도출되었는지 알기 어렵다.
import numpy as np
x_original = np.array([[2,3], [5,1]])
x = x_original.reshape(-1)
x_T = x.reshape(-1,1)
W = np.array([[2,1,-3,3], [1,-3,1,3]])
b = np.array([[3],[3]])
weight_sum = W@x_T + b
weight_sum
res = 1/(1+ np.exp(-weight_sum))
print(res)

> 다수의 퍼셉트론을 다층 퍼셈트론, 신경망이라고 한다

> 입력층의 node는 피처의 개수 예) 포도의 이미지의 픽셀 데이터
> 출력층의 개수는 타깃의 개수 예) 포도, 레몬
> 은닉층이 중요하지만 정해진 크기가 없고 잘 작동되는지 알 수 없다.
> 입력층은 1층, 은닉층은 층의 제한이 없다.
> 딥러닝에서의 딥은 은닉층이 깊다라는 뜻.
> 정할 수 있는 부분은 은닉층의 층, 각 층의 노드 수, 각 층의 활성화 함수이다.
> 공식이 없어서 잘 나올 때까지 돌려야 한다.
> 은닉층마다 노드 크기가 다르게 할 수 있다.
> 여러 층을 만들 때 노드를 늘릴 때 1.5배나 2배 등 크게 늘린다.
> 한 층은 동일한 활성화 함수를 사용한다.
> 은닉층을 적게 시작해서 늘리는 걸 추천
> 딥러닝 소요 시간은 sklearn보다 훨씬 크다.
> 예측의 문제의 경우 출력층은 타깃의 노드 개수는 하나이고 그 값이 예측값이 된다.

> 은닉층은 합성 함수 개념과 비슷하다

> 계산식이 Wx+b 간단하지만 계산량이 너무 많은 게 문제다.

> 순전파는 피처를 신경파에 태우면 y1, y2값이 나오고 역전 파는 반대로.
> 순전파, 역전파 반복으로 w를 업데이트한다.
> 반복 횟수가 매우 크다.

> 가중치 초기화는 random으로 한다.
> 순전파 구하고 Loss가 나오고 미분해 주고 Loss값 구한다


> w 초기값을 Random 한 값을 준다
> w11은 x1이 g1으로 가는 화살표의 가중치이다.
> 은닉 층 1개, 노드 2개


> 이 값은 g1과 g2가 된다.



> z1, z2 값


> 오차는 계산한 y1 값과 실제값 t를 빼고 제곱합을 한다.
> 1/2는 scaler로 미분 편하게 하기 위함이다.
> 비용 함수는 C or L(Loss Function)으로 표시한다.
> 예측값 변화에 따른 비용의 변화율은 (yn의 편미분값, gradient 값) 둘 간의 차이만큼 변한다.



> 역순으로 갈 땐 Gradient를 구한다.

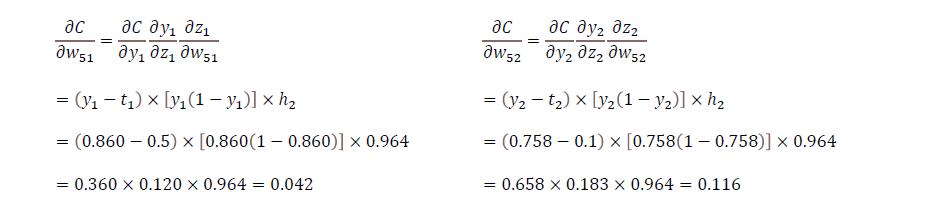


> 궁극적으로 w에 따라 C 값을 아는 것이 목적이다.
> 직접적으로 구할 수 없어서 연쇄 법칙 이용해서 구한다.
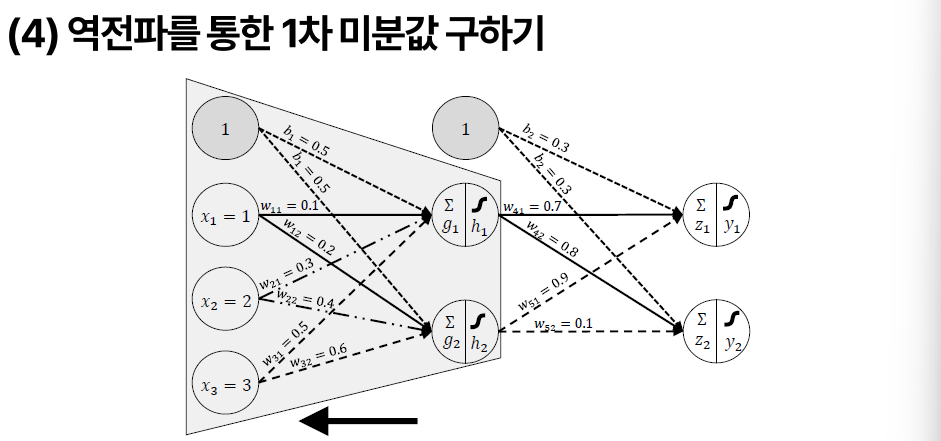





> 학습률은 한 걸음을 얼마나 갈 거냐의 척도.
> 이게 업데이트 한 번이고 이 반복을 수천수만 번 진행하고 w 업데이트 값이 안 움직일 때까지 반복한다.
> 어떤 피처가 중요한지 알 수 없다.




> -1 < y < 1 범위를 갖도록


> 최근에 많이 쓰임
> 0보다 작으면 버리기 좀 아까워서 기울기를 줘서 0 보다 작은 값을 챙김

> 가중합을 그대로 사용

> Input들이 그전 노드들의 값들을 다 넣는다는 게 다른 함수와 차이점
> 그전 활성화 함수는 다른 노드 영향을 안 받는데 softmax는 아니다.
> y1 + y2는 1이고 확률이다.
> 분류 문제에서 최종층의 활성화 함수는 softmax를 써야 한다.


> 성능 평가를 크로스 엔트로피를 활용한다.
> Pytorch엔 softmax 함수와 크로스 엔트로피가 합쳐져 있다.

> 예측 문제는 최종층의 활성화 함수를 항등 함수를 사용한다. (이유는 잘 맞아서)
> 평가는 mse로 한다.

> 데이터 하나에 대해선 손실, 데이터 전체에 비용이라고 한다.

> 꼭 써야 되는 건 아님

> 순전, 역전하면서 안 쓰는 노드가 바뀜, 오버 피팅은 방지 (꼭 써야 되는 건 아님)

> training Data 미니 배치로 쪼개서 미니 배치 당 가중체 업데이트해서 계산을 줄이는 방법.

> 100개의 베치가 7번 iteration 하고 전체 데이터에 대해서 다 하면 이걸 1 에포크(epoch)라고 한다.
> 에포크의 수는 Hyper Parameter이고 보통 1000번은 함.
> 1 에포크의 시간이 중요하다, 작업의 사이즈를 확인 척도로 볼 수 있다.

> Pytorch는 속도 Oriented 된 Library, User Friendly 하지 않다.

> random_state를 전역에 선언한다. (많아서 함수마다 정하기 어렵기 때문)


> 피처, 타깃 분류,. values를 해줘야 array 형식으로 나옴.
> list를 겹겹이 싸면 numpy array, array를 겹겹이 싸으면 pandas
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, random_split, DataLoader
device = 'cpu'
if torch.cuda.is_available(): #cuda 사용하면 cuda 사용
device = 'cuda'
torch.manual_seed(777)
if device =='cuda':
torch.cuda.manual_seed_all(777)
df = pd.read_csv('./data/iris.csv')
X = df.iloc[:, :-1].values #values를 해줘야 array 형태로 됨
y = df.iloc[:,-1].values

> numpy data를 pytorch data 형태로 변환
> float32로 해야 돌아감
>. to(device) 안 써도 되는데 나중에 cuda 쓸 경우엔 써줘야 함.


> 피처랑 타깃 데이터를 묶어준다.
> 데이터 셋 확인하려면 for 문 돌려서 확인해야 된다.
> 낯개 포장해야 분산 처리할 수 있기 때문에 DataFrame마록 TensorDataset으로 나눈다.
> training Data 개수, Test Data 개수 나눠준다.
> FloatTensor는 Tensor flow의 초창기 문법, 최근은 torch.tensor로 많이 활용됨.
X = torch.tensor(X, dtype = torch.float32).to(device)
y = torch.tensor(y, dtype = torch.long).to(device)dataset = TensorDataset(X,y)
n=len(dataset)
ratio_n = 0.8
n_tn = int(n*ratio_n)
n_te = n - n_tn
for i in range(0,5):
print(dataset[i])



> 미니 배치를 나주는 작업
> 계산을 빠르게 하기 위해서 8의 배수로 보통 정하는 관습이 있지만 필수는 아니다.
> Shuffle은 iteration 돌고 섞은 건지 여부
train_data, test_data = random_split(dataset, [n_tn, n_te])
for i in range(0,3):
feature, target = train_data[i]
print('Input : ',feature)
print('Label : ',target)
n_batch = 16
train_loader = DataLoader(train_data, batch_size = n_batch, shuffle = True)

batch_count = 0
for batch in train_loader:
features, labels = batch
print('features ', features)
print('labels', labels)
print()
batch_count += 1
if batch_count >=2:
break

> Hyper Parameter 설정
> train_data [0][0]

> 신경망 class를 만들어준다.
> nn.Module 상속을 받는다.
> super(Classifier, self) 부모의 init을 불러옴
> n_features는 피처의 개수
> fc1는 full connect, nn.Linear를 불러오는데 하나의 은닉층 (wx+b의 layer)이고 (n_feature, 10)
> n_feature는 노란색 즉 피처의 개수, 10은 녹색의 10개의 node
> Leakyrelu는 활성화 함수
> fc2는 활성화 함수에서 target이다. (10, 3)
> fc1, fc2 연결하는 node의 수는 일치해야 한다.
> 예측 문제는 마지막 숫자가 1이다.
> forward는 함수 overiding 한다.
> x가 fc1 타고 활성화 함수 탄 다음 fc2 타서 값이 나온다.
> return x는 필수
> Backward는 만들 필요 없다.
> 데이터 전처리 하지 않는다. (해도 된다)
learning_rate = 0.01
epochs = 1000
n_feature = len(train_data[0][0])
class Classifier(nn.Module):
def __init__(self, n_feature):
super(Classifier, self).__init__()
self.fc1 = nn.Linear(n_feature, 10)
self.leakyrelu = nn.LeakyRelU()
self.fc2 = nn.Linear(10, 3)
def forward(self, x):
x = self.fc1(x)
x = self.leakyrelu(x)
x = self.fc2(x)
return x
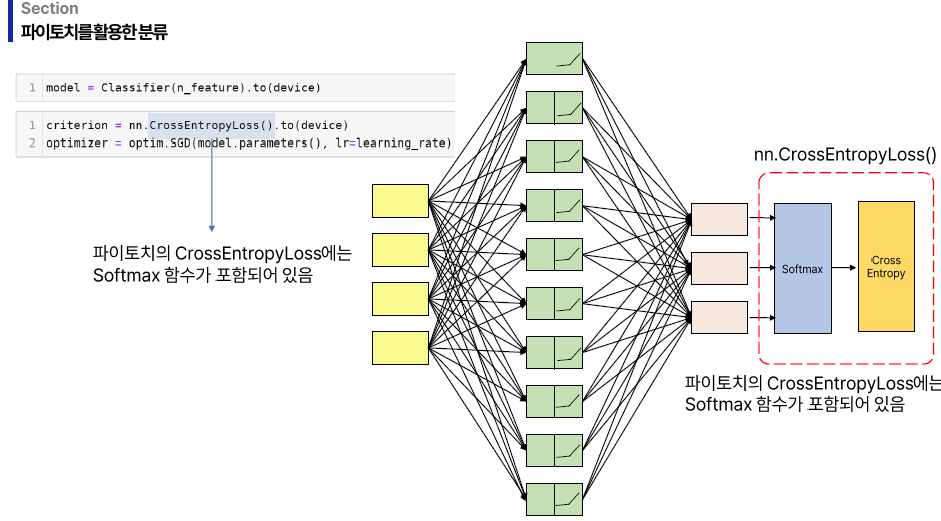
> CrossEntropyLoss 안에 Softmax도 포함
> Optimzation은 SGD 말고 다른 것도 가능
model = Classifier(n_feature).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr = learning_rate)

> 추론 모드는 순전파 결과 값만 return
> 학습 모드에선 dropout layer가 활성화가 되고 추론 모드에선 안되고 모든 노드가 활성화된다.

> zero_grad : 그 레이던트 초기화
> model.forward 순전파 진행해서 criterion에서 엔트로피와 soft max 산출
> y_hat은 엄밀히 말해서 추정값이 아님 (soft max 거쳐야 함)
> optimizer.step은 한 발자국 더 나아간다
> 미니 배치가 반복될 때 마다 그레디언트를 초기화한다. / 안 하면 학습하다가 폭발할 수 있다.
> 100번 돌 때마다 cost 출력
total_batch = len(train_loader)
model.train()
for epoch in range(epochs):
avg_cost = 0
for X_tn, y_tn in train_loader:
X_tn = X_tn.to(device)
y_tn = y_tn.to(device)
optimizer.zero_grad()
y_hat = model.forward(X_tn)
cost = criterion(y_hat, y_tn)
cost.backward()
optimizer.step()
avg_cost += cost/total_batch
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Cost: {avg_cost:.4f}')

> y^hat은 soft max 전의 값 (확률은 아님)

> Stack을 통해 다시 합쳐줘야 함
X_te = []
y_te = []
for row in test_data:
feature, target = row
X_te.append(feature)
y_te.append(target)
X_te = torch.stack(X_te)
y_te = torch.stack(y_te)


> torch.argmax(prediction, 1) 가장 큰 Index를 찾아서 1번 열에 (타깃) 값을 반환하고 y_te와 비교해서 동일한지 Boolean
> 1은 즉 dimension임
> accuracy.item()은 텐서의 값을 파이썬의 스칼라 값으로 변환하여 반환하는 메서드
with torch.no_grad():
model.eval() #추론 모드 evaluation
prediction = model.forward(X_te)
correct_prediction = torch.argmax(prediction, 1) == y_te
accuracy = correct_prediction.float().mean()
print('accuracy ', accuracy.item())


> 모델의 상태를 저장 (Weight를 저장한다)
> 예측할 땐 저장한 모형을 load해서 사용한다.
PATH = './iris_model01.pt'
torch.save(model.state_dict(), PATH)
loaded_model = Classifier(n_feature).to(device)
loaded_model.load_state_dict(torch.load(PATH, weights_only=True))
with torch.no_grad(): #그레디언트를 비활성화 평가 모드
loaded_model.eval()
prediction = loaded_model(X_te)
correct_prediction = torch.argmax(prediction, 1) == y_te
accuracy = correct_prediction.float().mean()
print(accuracy.item())
회귀
> Batch Normalization : 각 Node를 평균 0, 분산 1로 만드는 과정
> BatchNorm1d (1d는 벡터), 이미지는 BatchNorm2d 해야 함
> Dropout은 random으로 portion 만큼 버림
> backward()에서 optimizer 넘기는 건 Pytorch에서 알아서 해줌
#딥러닝 회귀
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, random_split, DataLoader
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
torch.manual_seed(0)
if device == 'cuda':
torch.cuda.manual_seed_all(0)
df = pd.read_csv('./data/house_prices.csv')
X = df.iloc[:,:-1].values
y = df.iloc[:,-1].values
X = torch.tensor(X, dtype=torch.float32).to(device)
y = torch.tensor(y, dtype=torch.float32).to(device)
dataset = TensorDataset(X,y) #합치는 부분
n=len(dataset)
ratio_n = 0.8
n_tn = int(n * ratio_n)
n_te = n - n_tn
train_data, test_data = random_split(dataset, [n_tn, n_te])
train_loader = DataLoader(train_data, batch_size = 16 , shuffle = True) # 미니 배치
learning_rate = 0.01
epochs = 1000
n_feature = len(train_data[0][0])
class Regressor(nn.Module):
def __init__(self, n_featrue):
super(Regressor, self).__init__()
self.fc1 = nn.Linear(n_feature, 30)
self.bn1 = torch.nn.BatchNorm1d(30)
self.relu = nn.ReLU()
self.dropout = torch.nn.Dropout(p=0.3)
self.fc2 = nn.Linear(30,1)
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
model = Regressor(n_feature).to(device)
criterion = nn.MSELoss().to(device)
optimizer = optim.SGD(model.parameters(), lr = learning_rate)
total_batch = len(train_loader)
model.train()
for epoch in range(epochs):
avg_cost = 0
for X_tn, y_tn in train_loader:
X_tn = X_tn.to(device)
y_tn = y_tn.to(device)
optimizer.zero_grad()
y_hat = model.forward(X_tn)
y_hat = y_hat.squeeze()
cost = criterion(y_hat, y_tn)
cost.backward()
optimizer.step()
avg_cost += cost/total_batch
X_te = []
y_te = []
for row in test_data:
feature, target = row
X_te.append (feature)
y_te.append(target)
X_te = torch.stack(X_te)
y_te = torch.stack(y_te)
with torch.no_grad():
model.eval()
prediction = model.forward(X_te)
prediction = prediction.squeeze()
mse = criterion(prediction, y_te)
print(mse)
> 다른 사람 신경망 노드 참고 가능
Hugging Face – The AI community building the future.
huggingface.co
> 여기까지 기초분류/기초 회귀
CNN (Convolution)
> 합성 곱 신경망
> 이미지 처리는 CNN
> Input Data는 최소 Matrix ~ Tensro (피처)
> Input 이 3차원이면 은닉층도 3차원이다.
> 은닉층을 벡터로 펼쳐서 분류한다
> 은닉층의 역할이 나눠진다 큰 그림에서 더 디테일한 거로 근데 컴퓨터가 알아서 한다.
> 이미지 처리는 보통 원인이 필요 없다
> Tensor로 신경망 짜는 게 어렵다.
> 주석으로 이해 안 되는 경우도 있어서 그림으로 이력을 잘 남겨야 한다.
> 기초 이후의 것들은 코드가 다 어려워짐

Auto Encoder
> 신경망이 보통 나비 모양으로 생겼음
> 줄어드는 앞부분을 Encoding, 뒷부분을 Decoding이라고 한다.
> 신경망을 두 개 만들어서 붙이는 과정 (핵심 내용을 빼내는, 차원 축소처럼)
> 피쳐 개수랑 출력 노드 개수가 같음, 비지도 학습이고 추천 시스템에 쓰인다.
> 이미지 노이즈 제거에도 사용된다.
> Input과 Output 크기가 같은 경우 많이 쓰임.

RNN
> 순호나 신경망 (Recurrent)
> 출력을 하나 보내고 다시 입력으로 넣어서 다시 연산함 (Feed Back 개념)
> 안을 집어넣으려면 word2 vect로 vector 변환하고 은닉층을 통과하고 결과가 하나 나온다고 가정해 보면
> 결과 나온 걸 입력이랑 같이 다시 은닉층으로 다시 넣는다.
> 안 넣으면 반이 나오면 반이랑 녕을 다시 넣고 습이 나오고 습이랑 하랑 같이 넣고 계속 반복하면
> 안녕하세요 입력이 반갑습니다로 나옴.
> 번역, text, 시계열 데이터에 활용됨.
LSTM (RNN + 게이트 추가)
> 신경망 안에 게이트를 넣는다.
> 게이트로 신경망 탄 거를 다음으로 넘길지 말지 조절한다.
Seq2 Seq (RNN + Auto Encoder)
> Input data 길이와 Output data 길이가 다를 때 사용.
> RNN에서 중요도를 평가해서 보는 게 attention.
> attention 구조로 만든 게 transformer
> 이걸 가지고 만든 게 Chat GPT
만든 모델 배포하는 방법
1. Python으로 파일 업로드, 판단하는 프로그램 만들면 된다.
> pyQT 활용하면 된다.
2. 서버를 빌려서 모델을 올려서 24시간 돌려서 접근할 수 있도록 함 (Restful API)
> flask, fastAPI 라이브러리 활용.
> 네트워크가 연결되어 있어야 한다.
'Machine Learning 입문' 카테고리의 다른 글
| 11. 시계열 분석 (0) | 2024.12.28 |
|---|---|
| 10. 비지도 학습 (1) | 2024.12.28 |
| 9. 앙상블 학습 (3) | 2024.12.28 |
| 8. 지도 학습 (0) | 2024.12.26 |
| 7. 최적화 & 모형 평가 (1) | 2024.12.26 |
- Total
- Today
- Yesterday
- 양자 웰
- Depletion Layer
- Energy band diagram
- EBD
- Fiber Optic
- Pinch Off
- Diode
- fermi level
- channeling
- Solar cell
- Charge Accumulation
- semiconductor
- Optic Fiber
- Donor
- 반도체
- Laser
- Reverse Bias
- Acceptor
- C언어 #C Programming
- 쇼트키
- Semicondcutor
- 열전자 방출
- Thermal Noise
- pn 접합
- PN Junction
- CD
- MOS
- 문턱 전압
- Blu-ray
- 광 흡수
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |